
Exploration von Empfehlungsdiensten - Klasse 8 bis 10
Hinweis: Dieses Unterrichtsmodul befindet sich noch in der Erprobungsphase und wird von uns noch evaluiert sowie überarbeitet. Bei Interesse an Erprobungen melden Sie sich gerne bei Lukas Höper aus der Didaktik der Informatik.
{{#if:Datei:ProDaBi Logo.png|
}}
{{#if:Datenbewusstsein| }} {{#if:Lukas Höper| }} {{#if:Medium:Datenbewusstsein Unterrichtsmodul Klasse 8 bis 10.zip| {{#if:Download aller Materialien zum Modul| | }} }} {{#if:| {{#if:| | }} }} {{#if:| {{#if:| | }} }} {{#if:| {{#if:| | }} }} {{#if:| {{#if:| | }} }} {{#if:| }}| Themenfeld | Datenbewusstsein |
|---|---|
| Autor | Lukas Höper |
| Editiert am | 17.7.2023 |
| Material | Download aller Materialien zum Modul |
| Material | Medium:Datenbewusstsein Unterrichtsmodul Klasse 8 bis 10.zip |
| [[:|]] | |
| [[:|]] | |
| [[:|]] | |
| [[:|]] | |
| [[:|]] | |
| [[:|]] | |
| [[:|]] | |
| [[:|]] | |
| Unterseiten |
Daten spielen im alltäglichen Leben in der digitalen Welt uns bewusst oder auch unbewusst eine große Rolle. Schülerinnen und Schüler interagieren tagtäglich mit verschiedenen datengetriebenen digitalen Artefakten (z.B. der News Feed auf einer Social Media Plattform oder die Startseite bei etwa Netflix oder Spotify). In diesem Unterrichtsmodul werden Empfehlungsdienste (engl. Recommender Systems) als Beispiel für datengetriebene digitale Artefakte thematisiert, bei deren Nutzung verschiedene Daten explizit und implizit erhoben und generiert werden, wie etwa Bewertungsdaten der Nutzerinnen und Nutzer. Konkret wird dazu exemplarisch ein Filmempfehlungsdienst im Kontext von Streamingdiensten aufgegriffen. Anhand dieses Beispiels soll in diesem Unterrichtsmodul eine Förderung des Datenbewusstseins der Schülerinnen und Schüler stattfinden, wozu die Leitfrage „Wo, wie und wozu werden Daten gesammelt und verarbeitet?“ beispielhaft beantwortet wird.
Steckbrief des Unterrichtsmoduls
Titel: Wo, wie und wozu werden Daten gesammelt und verarbeitet? – Datenbewusstsein durch die Exploration von Empfehlungsdiensten im Kontext von Streamingdiensten
Stichworte: Datenbewusstsein, Data Science, Exploration von Empfehlungsdiensten
Zielgruppe: Informatik in Klasse 8 bis 10 (alle Schulformen)
Inhaltsfeld: "Informatik, Mensch und Gesellschaft" (Schwerpunkt: Datenbewusstsein), "Information und Daten", "Informatiksysteme" und "Künstliche Intelligenz und maschinelles Lernen"
Vorkenntnisse: Dieses Unterrichtsmodul setzt keine besonderen Vorkenntnisse der Lernenden voraus. Es sollte jedoch eine grundlegende Erfahrung im Umgang mit dem Computer vorhanden sein. Außerdem sind grundlegende Vorstellungen des Datenbegriffs wünschenswert, entsprechende Einführungen könnten aber auch in diesem Modul integriert werden. Ein Verständnis von Künstlicher Intelligenz oder Maschinellem Lernen ist nicht nötig, im Gegenteil werden in diesem Modul Aspekte dessen bereits aufgegriffen – diese könnten auch in einer Adaption des Unterrichtsmoduls erweitert werden.
Zeitlicher Umfang: 6-8 Unterrichtsstunden a 45 Minuten
Überblick über den Verlauf des Unterrichtsmoduls
Dieses Unterrichtsmodul vermittelt Datenbewusstsein: Die Kompetenz, sich der Rolle der (persönlichen) Daten bei der Nutzung unterschiedlicher Anwendungen bewusst zu werden, um schließlich deren Nutzung zu bewerten und eigene Handlungsoptionen identifizieren zu können. Damit wird das Ziel verfolgt, die Lernenden zu einer selbstbestimmten Interaktion mit datengetriebenen Anwendungen in ihrem Alltag zu befähigen. Das Modul setzt sich aus vier Teilen zusammen und thematisiert exemplarisch die Erhebung und Verarbeitung von persönlichen Daten bei der Nutzung von Streamingdiensten, bei denen Empfehlungsdienste eingesetzt werden. Fokussiert wird die Rolle der Daten für einen Empfehlungsdienst, wie etwa bei der Startseite bei einem Streamingdienst zu erkennen, wobei weiterführend auch andere Alltagskontexte der Lernenden aufgegriffen werden.
Im ersten Teil wird in Empfehlungsdienste als Kontext und in die Idee der personalisierten Filmempfehlungen eingeführt. Dabei wird erarbeitet, welche persönlichen Daten bei der Nutzung eines exemplarischen Streamingdienstes, insbesondere für den primären Zweck des Gebens von personalisierten Filmempfehlungen, erhoben werden. Zum Beispiel sind dafür Nutzungsdaten interessiert, wie etwa welche Filme ein Nutzender zuvor geschaut hat. Dabei entwickeln die Lernenden bereits erste Ideen, was es bedeutet, einem Nutzenden Empfehlungen anzuzeigen und wie solche Filmempfehlungen ermittelt werden könnten.
Im zweiten Teil wird die Funktionsweise eines Filmempfehlungsdienstes rekonstruiert, wofür die Lernenden in einer vorbereiteten Lernumgebung mit einem funktionierenden Filmempfehlungsdienst (basierend auf realen Nutzungsdaten aus dem Streamingkontext) interagieren und schrittweise die Funktionsweise von der Erhebung von Daten bis hin zur automatisierten Ermittlung von Empfehlungen mit einem Verfahren des maschinellen Lernens erarbeiten (umfassende Erklärung des Empfehlungsdienstes sowie des ML-Verfahrens s.u.).
Im dritten Teil wird exemplarisch eine Zweitverwertung der Nutzungsdaten durch einen Streamingdienst thematisiert, indem eine Diskussionsrunde zu dem sekundären Zweck einer personalisierten Bezahlschranke basierend auf der Idee des Empfehlungsdienstes betrachtet wird. Dabei wird der Interaktionskontext hinsichtlich der Erhebung und Verarbeitung persönlicher Daten reflektiert und Handlungsoptionen insbesondere auf einer individuellen Betrachtungsebene bedacht und bewertet. In diesem Teil werden verschiedene Aspekte der Wechselwirkung zwischen Nutzendem und dem Streamingdienst (mit Fokus auf Empfehlungsdienste) thematisiert, wie etwa Verstärkungen von Abhängigkeiten im Nutzungsverhalten oder Wirkungen im Sinne der Idee von Filterblasen.
Im vierten Teil werden die gemachten Erfahrungen auf weitere mögliche Kontexte übertragen und so verallgemeinert, indem die Lernenden weitere datengetriebene Anwendungen aus ihrem Alltag untersuchen, in denen Empfehlungsdienste eingesetzt werden, wie zum Beispiel bei bestimmten Apps auf ihrem Handy. Im Rahmen einer Evaluation und Bewertung der Datenerhebung und -verarbeitung in den verschiedenen Beispielen können Vor- und Nachteile der Erhebung und Verarbeitung persönlicher Daten (z.B. Nutzungsdaten) diskutiert werden, um so den Lernenden eine Grundlage für reflektierten Entscheidungen hinsichtlich der Interaktion mit datengetriebenen Anwendungen dieser Art zu vermitteln.
Didaktische Kernidee: Förderung von Datenbewusstsein in diesem Unterrichtsmodul
Zur Umsetzung der Ziele und damit zum Fördern des Datenbewusstseins der Lernenden werden die Facetten von Datenbewusstsein in den vier Teilen des Unterrichtsmoduls umgesetzt. Das gewählte Beispiel im ersten Teil beschreibt ein Interaktionssystem bestehend aus einem Nutzendem und einem Streamingdienst bzw. dessen Empfehlungsdienst als datengetriebenes digitales Artefakt sowie der Interaktion zwischen diesen. Durch ein Spiel zu personalisierten Filmempfehlungen erarbeiten die Lernenden im ersten Teil die Bedeutung von personalisierten Filmempfehlungen und welche Rolle dabei Informationen bzw. Daten über die Person spielen. Dabei entwickeln sie Ideen für die explizite und implizite Erhebung von persönlichen Daten für den primären Zweck der Verwendung dieser Daten, des Ermittelns von personalisierten Filmempfehlungen. Diesen primären Zweck im Sinne der automatisierten Ermittlung von personalisierten Filmempfehlungen durch einen Empfehlungsdienst erarbeiten die Lernenden im zweiten Teil detaillierter. Dabei werden insbesondere auch die Konstruktion und Bedeutung des digitalen Doppelgängers eines Nutzenden hervorgehoben. Für einen sekundären Zweck der Verwendung und Verarbeitung der erhobenen Daten oder auch der digitalen Doppelgänger von Nutzenden wird im dritten Teil eine exemplarische, fiktive personalisierte Bezahlschranke thematisiert, in der verschiedene Aspekte der Wechselwirkungen in dem Interaktionssystem aufgegriffen werden. Dies veranlasst die Lernenden die Rolle der Daten und des Selbst in diesem exemplarischen Interaktionssystem zu reflektieren und die Erhebung und Verarbeitung von persönlichen Daten in einem solchen Interaktionssystem zu bewerten. Im vierten Teil werden die erlernten Kenntnisse zum Datenbewusstsein auf weitere Beispiele aus ihrem eigenen Alltag angewandt: Interaktion mit einem datengetriebenen digitalen Artefakt; explizite und implizite Datenerhebung; primäre und sekundäre Zwecke der Verwendung und Verarbeitung sowie Konstruktion eines digitalen Doppelgängers. Diese Kontexte werden anschließend reflektiert und kriteriengeleitet bewertet.
Ziele des Unterrichtsmoduls
In den vier Teilen des Unterrichtsmoduls werden im Wesentlichen folgende Ziele verfolgt:
- Teil 1: Filmempfehlungen und Datenerhebung durch einen Empfehlungsdienst
- Die Lernenden erkennen die Bedeutung von personalisierten Filmempfehlungen, indem sie exemplarisch anderen Lernenden in mehreren Schritten Filmempfehlungen geben und diesen Prozess der Verbesserung dieser Filmempfehlungen reflektieren.
- Die Lernenden unterscheiden die Begriffe der explizit und implizit erhobenen Daten und entwickeln Ideen dafür, welche Daten für die automatisierte Ermittlung von Filmempfehlungen explizit und implizit erhoben werden.
- Die Lernenden begründen exemplarisch die Notwendigkeit der expliziten und impliziten Erhebung von persönlichen Daten sowie deren Verarbeitung zum Ermitteln personalisierte Filmempfehlungen beispielhaft für die Erstellung einer Startseite bei einem Streamingdienst (primärer Zweck).
- Teil 2: Aufbau und Funktionsweise von Filmempfehlungsdiensten
- Die Lernenden erklären wesentliche Schritte zur automatisierten Ermittlung von personalisierten Filmempfehlungen basierend auf explizit und implizit erhobenen Daten (z.B. Nutzungsdaten), wobei sie auf die Grundidee des kollaborativen Filterns anhand des Verfahrens k-nearest-neighbors aus dem maschinellen Lernen eingehen.
- Die Lernenden beschreiben die Konstruktion eines digitalen Doppelgängers bei der Nutzung eines Streamingdienstes und begründen dessen Relevanz für einen Empfehlungsdienst.
- Teil 3: Zweitverwertung durch einen Empfehlungsdienst
- Die Lernenden erkennen den Vorschlag der Zweitverwertung für eine personalisierte Bezahlschranke als Idee für einen sekundären Zweck der Verwendung und Verarbeitung der erhobenen Daten bzw. des digitalen Doppelgängers, indem sie diese Idee aus verschiedenen Perspektiven in einer Diskussionsrunde (bzw. Rollenspiel) beleuchten.
- Die Lernenden erkennen mehrere Aspekte der Wechselwirkung zwischen Nutzendem und Streamingdienst, indem sie diese im Rahmen der Diskussionsrunde aufgreifen und bewerten.
- Die Lernenden beschreiben aus ihrer individuellen Perspektive Handlungsoptionen bzgl. der Interaktion mit einem Streamingdienst mit einem Empfehlungsdienst, indem sie eine Bewertung bzgl. der Erhebung und Verarbeitung von Daten im Rahmen der Interaktion mit einem Streamingdienst vornehmen und ein Fazit dazu formulieren.
- Teil 4: Weitere Kontexte mit Empfehlungsdiensten
- Die Lernenden wenden ihre gelernten Kenntnisse zum Datenbewusstsein auf weitere Beispiele eines datengetriebenen digitalen Artefakts aus ihrem Alltag an, indem sie an diesem Beispiel die explizite und implizite Datenerhebung, deren Verwendung und Verarbeitung zu primären und exemplarischen sekundären Zwecken sowie die Konstruktion von digitalen Doppelgängern identifizieren und beschreiben.
- Die Lernenden nehmen eine begründete Bewertung der Erhebung und Verarbeitung von Standortdaten in den thematisierten Beispielen vor, indem sie zum Beispiel auf den Kompromiss zwischen einem datensparsamen Verhalten und das Nutzen von individuellen oder gesellschaftlichen Vorteilen eingehen.
Leitfragen im Unterrichtsmodul
- Teil 1: Filmempfehlungen und Datenerhebung durch einen Empfehlungsdienst
- Was sind personalisierte Filmempfehlungen, welche Daten über Nutzende sind dafür hilfreich und welche kann ein Streamingdienst explizit und implizit erheben?
- Teil 2: Aufbau und Funktionsweise von Filmempfehlungsdiensten
- Wie können anhand von u.a. Bewertungsdaten (anhand explizit und implizit erhobener Daten) automatisiert personalisierte Filmempfehlungen ermittelt werden? (primärer Zweck)
- Wie wird ein digitaler Doppelgänger von einem Nutzenden konstruiert und welche Rolle spielt dieser für die Funktionsweise im Empfehlungsdienst?
- Teil 3: Zweitverwertung durch einen Empfehlungsdienst
- Wozu könnten persönliche Daten neben dem Zweck der Ermittlung personalisierter Filmempfehlungen ansonsten genutzt werden?
- Welche Bedeutung hat die Rolle der Daten im Rahmen der Nutzung von Streamingdiensten mit Empfehlungsdiensten hinsichtlich Aspekte der Wechselwirkung zwischen Nutzendem und dem Streamingdienst?
- Teil 4: Weitere Kontexte mit Empfehlungsdiensten
- In welchen anderen Kontexten werden Empfehlungsdienste eingesetzt, welche Daten werden dort erhoben und wozu werden sie verarbeitet?
- Welche Handlungsoptionen hat ein Nutzender in diesen Kontexten?
Zusammenfassender Überblick über das Unterrichtsmodul
Das Unterrichtsmodul mit den zentralen Aktivitäten, Leitfragen und Fachinhalten in den drei Teilen wird in der nachfolgenden Grafik zur Übersicht und Orientierung zusammengefasst.
{kind=link}
Überblick über das Unterrichtsmodul
In der folgenden überblicksartigen Tabelle wird der Unterrichtsverlauf beschrieben. Die Materialien für die verschiedenen Phasen (Arbeitsblätter und Zusatzmaterialien) werden in der Tabelle entsprechend verlinkt. Als Unterstützungsmaterial für Lehrkräfte steht ebenfalls eine Handreichung mit ergänzenden Informationen bereit, in der ausgewählte Inhalte des Unterrichtsmodul, Materialien und Begrifflichkeiten näher erklärt werden. Diese Handreichung ist nicht als Unterrichtsmaterial gedacht. Diese finden Sie hier: Ergänzende Informationen
| Phase | Inhalt | Ziele | Material |
|---|---|---|---|
| 1a | Einführung in den Interaktionskontext und Problematisierung:
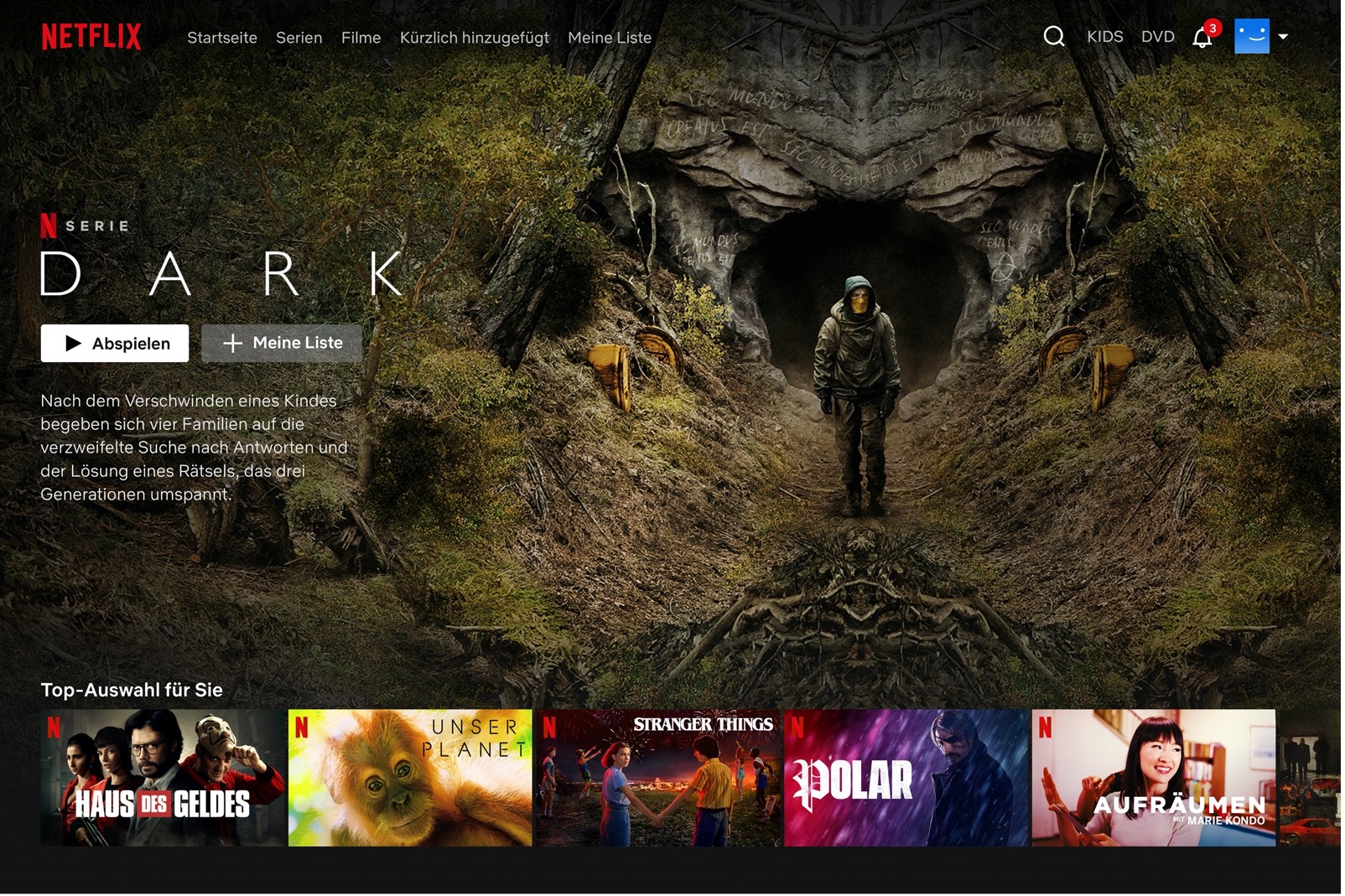
Es wird mit einem Unterrichtsgespräch in den Kontext eingestiegen, wozu beispielsweise das beiliegende Beispielbild einer Startseite von der Streamingplattform Netflix gezeigt wird. Das Unterrichtsgespräch wird im Wesentlichen an drei Leitfragen orientiert:
Das Beispiel aufgrund seiner Bekanntheit – insbesondere auch bei den Lernenden – gewählt. Dennoch gibt es Lernende, die dazu weniger Erfahrungen haben als andere, sodass in dieser Phase alle Lernenden mit ihren mehr oder weniger vorhandenen Erfahrungen abgeholt werden sollen. Das Unterrichtsgespräch soll gerade auf die letzte Leitfrage hinarbeiten und diese motivieren; in anderen Worten soll problematisiert werden, wie solche personalisierten Filmempfehlungen ermittelt werden können. |
|
Beispielbild einer Netflix-Startseite;
ggf. Aussage: „Für alle Nutzer:innen existieren eigene personalisierte Startseiten, keine doppeln sich.“; |
| 1b | Empfehlungsspiel: Bedeutung von Filmempfehlungen und zugehörige Datenerhebung
In Partnerarbeit bearbeiten die Lernenden das AB1, das eine Art „Empfehlungsspiel“ darstellt. Bei der Partnerarbeit dürfen die Lernenden nur in bestimmten Aufgaben miteinander sprechen und nicht darüber hinaus. Durch das gegenseitige Geben von Filmempfehlungen werden die Lernenden darin eingeführt, was eine personalisierte Filmempfehlung ausmacht. Sie erarbeiten, welche Informationen dafür hilfreich sind, und entwickeln Ideen für entsprechende Daten, die von einem Streamingdienst explizit und implizit erhoben werden könnten (Aufg. 4 auf AB1). In der Auswertung dieser Erarbeitungsphase wird ausgewertet, welche Empfehlungen besser passten (s. Aufg. 3 auf AB1) und welche Fragen dafür besonders hilfreich waren (s. Aufg. 2 auf AB1). Außerdem werden die Ideen für die explizit und implizit erhobenen Daten (s. Aufg. 4 auf AB1) gesammelt.
Didaktischer Kommentar: Mit dieser Erarbeitungsphase sollte den Lernenden deutlich werden, worauf es ankommt, gut passende personalisierte Filmempfehlungen zu ermitteln. Dafür sollten in der PA möglichst Lernende zusammenarbeiten, die sich nicht gut kennen. In dieser Partnerarbeit wechseln die Lernenden zwischen der Anbieter- sowie Nutzerperspektive und reflektieren dabei den eigenen Prozess zum Ermitteln von personalisierten Filmempfehlungen. Die Begrifflichkeiten der expliziten und impliziten Datenerhebung werden in der Aufgabe 4 des AB1 eingeführt. Sofern diese für die Lernenden zuvor unbekannt waren, könnte vor Aufgabe 4 eine Besprechung zur konzeptionellen Einführung der Begriffe stattfinden (s. Begriffserklärung). In der Auswertung der Erarbeitungsphase sollte dann einerseits auf die korrekte Einordnung von explizit und implizit erhobene Daten geachtet werden; andererseits sollte die Unterscheidung von Daten und Information berücksichtigt werden (z.B. sollte bei Daten nicht „Interesse“ stehen; die Frage ist doch viel mehr, welche Daten nötig sind, um Vermutungen zum Interesse einer Person aufzustellen). |
|
AB1 |
| 2a | Überleitung zum Empfehlungsdienst im Jupyter Notebook:
Mit Aufgreifen der vorherigen Leitfrage „Wie kommen Filmempfehlungen zustande?“ wird eine Überleitung zu diesem Teil 2 gemacht. Zuvor haben die Lernenden Ideen erarbeitet, welche Daten für das Finden von personalisierten Filmempfehlungen hilfreich sein könnten; offen ist jedoch noch, wie diese Daten denn verarbeitet werden, um solche Filmempfehlungen automatisiert zu ermitteln (also das, was die Lernenden bei AB1 im Kopf gemacht haben). Die Lehrkraft führt in das Jupyter Notebook und den Umgang damit ein. Dieses vorbereitete Jupyter Notebook hält einen „fertigen“ Filmempfehlungsdienst bereit (s. detaillierte Beschreibung unten).
Die noch offene Leitfrage aus Teil 1 wurde erst zur Hälfte beantwortet: Die Lernenden haben nun Ideen, welche Daten für einen Empfehlungsdienst explizit und implizit erhoben werden könnten; offen ist jedoch noch, wie damit dann automatisiert das gemacht werden soll, was die Lernenden intuitiv gemacht haben, um in der Partnerarbeit von AB1 personalisierte Filmempfehlungen zu geben. Je nach Vorerfahrungen der Lernenden kann hier mehr oder weniger auf viel auf die Bedienung eines Jupyter Notebooks eingegangen werden. Es sollte auf jeden Fall der Zellenaufbau eines Jupyter Notebooks sowie das Ausführen von Zellen geklärt werden. In der Überleitung wird die Verbindung zwischen dem vorherigen eigenständigen Geben von personalisierten Filmempfehlungen zu einer digitalen Variante geschlagen. |
|
Jupyter Notebook (s.u.) |
| 2b | Interaktion und erste Erkundung eines Empfehlungsdienstes:
Die Lernenden bearbeiten das gegebene Jupyter Notebook, in dem sie eigene Bewertungen von Filmen angeben und automatisiert personalisierte Filmempfehlungen angezeigt bekommen (Interaktion mit dem gegebenen Empfehlungsdienst). Zunächst rekonstruieren die Lernenden, welche Daten durch das gegebene Empfehlungsdienst explizit und implizit erhoben bzw. herangezogen wurden. Bei der Auswertung dessen sollte festgehalten werden, dass die Bewertungen sowohl eine Arte „explizite Bewertung“ explizit erhoben als auch Daten über das Anschauen von Filmen als eine Art „implizite Bewertung“ implizit erhoben werden. Bei dieser Auswertung wird ebenfalls das Konzept des digitalen Doppelgängers besprochen und gesichert, welches in dem Jupyter Notebook bereits dargestellt ist und somit transparent gemacht wird. Außerdem sollte darauf eingegangen werden, welche weiteren Informationen in einem digitalen Doppelgänger in diesem Kontext enthalten sein könnten.
Zunächst bekommen die Lernenden einen funktionierenden Empfehlungsdienst gegeben und rekonstruieren daran, welche Daten diesem Empfehlungsdienst vorliegen. Dabei sollte ein Bezug zu ihren Ideen aus AB1 hergestellt werden. Dabei sollten deutlich werden, welche explizit und implizit erhobenen Daten in diesem Jupyter Notebook tatsächlich herangezogen werden, damit in der nachfolgenden Rekonstruktion der Funktionsweise des Empfehlungsdienstes die Datengrundlage und dessen Bedeutung klar ist. Zu Beginn des Jupyter Notebooks werden bereits automatisiert Filmempfehlungen gegeben. Für die folgenden Phasen der Rekonstruktion steht die Leitfrage im Mittelpunkt, wie diese Empfehlungen zustande kommen. |
|
Jupyter Notebook (s.u.) |
| 2c | Rekonstruktion der automatisierten Ermittlung von personalisierten Filmempfehlungen:
Schrittweise erarbeiten die Lernenden anhand des Jupyter Notebooks, wie personalisierte Filmempfehlungen exemplarisch basierend auf den Bewertungs- bzw. Nutzungsdaten systematisch ermittelt werden können. Zunächst wird dies anhand eines reduzierten, händisch zu verarbeiteten Datenbeispiels rekonstruiert und anschließend mithilfe eines ML-Verfahrens umgesetzt.
Reduziertes Beispiel von „Hand“: Anhand des reduzierten Beispiels mit fünf Nutzenden und drei Filmen rekonstruieren die Lernenden die systematische Idee der kollaborativen Filtermethodik basierend auf Ähnlichkeiten von Nutzenden (d.h. es werden ähnliche Nutzende gesucht und anhand derer Bewertungs- / Nutzungsdaten wird entschieden, ob ein dritter Film einem Nutzenden empfohlen werden sollten (s. detaillierte Beschreibung in Abs. 9.1 und 9.4).
Größeres Beispiel mit ML-Methode: Die Lernenden erarbeiten in dem Jupyter Notebook anschließend stark geleitet die automatisierte Berechnung personalisierter Empfehlungen, wozu k-nearest-neighbor als ML-Methode genutzt wird, um automatisiert und basierend auf den Daten zu allen verfügbaren Filmen ähnliche Nutzende zu ermitteln (s. detaillierte Beschreibung in Abs. 9.4). Als Grundlage für diese Bearbeitung dient gerade die vorherige reduzierte Ermittlung personalisierter Filmempfehlungen. Als optionale Sprinteraufgabe können sich die Lernenden über das sogenannte Cold-Start Problem Gedanken machen (s. AB2). Die Lernenden befassen sich mit der Frage, inwiefern der primäre Zweck erfüllt werden kann, wenn ein Nutzender noch keinen digitalen Doppelgänger hat bzw. wenn ein neuer Inhalt hinzugefügt wird. Zwischen der händischen und der automatisierten Ermittlung von Filmempfehlungen kann bei Bedarf eine Zwischensicherung eingeschoben werden, um insbesondere die Idee der Ähnlichkeit und die darauf basierende Ermittlung der Vorhersage für ein Bewertungsmaß sowie Entscheidung für oder gegen die Empfehlung eines Films zu sichern. In der Auswertung werden Vorgehen zur Ermittlung der ähnlichen Nutzenden, das Aufstellen eines Modells (und dessen Bedeutung) sowie die Ermittlung der Vorhersagewerte (für Ratings) besprochen, sodass anschließend exemplarisch Wege zur Auswahl von Filmen für die personalisierte Empfehlung reflektiert werden können. Außerdem sollte insbesondere auch darauf eingegangen werden, dass das kollaborative Filtern im Endeffekt ein „Verbinden und Vergleichen“ von digitalen Doppelgängern ist, sodass der eigene digitale Doppelgänger auch bei den Filmempfehlungen anderer Personen eine Rolle spielt (und andersherum). Hierbei sollte ebenfalls aufgegriffen werden, dass die Vorhersagewerte (s.o.) ebenfalls als Information im digitalen Doppelgänger enthalten sind und dieser somit ebenfalls Daten mit Vorhersagen zum zukünftigen Interaktionsverhalten enthält. Ggf. kann in der Auswertung die Idee des Cold-Start Problems aufgegriffen werden, beispielsweise indem dies von einzelnen Lernenden, die sich damit befasst haben, zusammen mit ihren Lösungsideen vorgestellt wird.
Zunächst wird sich auf zwei Filme beschränkt. Es werden also nur die Daten zu zwei Filmen betrachtet, um damit Empfehlungen „nicht-automatisiert“ zu ermitteln. Dies dient zunächst zur Vereinfachung, um die Idee der Ähnlichkeit einzuführen. Die hierbei verfolgte Idee ist vergleichbar mit dem Prinzip der ML-Methodik k-nearest-neighbors, die darauffolgend für die automatisierte Ermittlung personalisierter Filmempfehlungen genutzt wird. Diese Methode ist ein Beispiel, mit dem Zusammenhänge zwischen Nutzenden ermittelt werden können. Es werden also gerade zu einem festgelegten Nutzendem ein individuelles Cluster von ähnlichen Nutzenden ermittelt. Diese haben zu ihm/ihr scheinbar ein ähnliches Filminteresse. Dabei gilt die Grundannahme, dass die Filme, die die ähnlichen Nutzende interessant fanden, auch für die festgelegte Person vermutlich interessant sind. Für das ML-Verfahren könnten auch noch weitere Aspekte von ML integriert werden, wie etwa die Performance von ML-Modellen und dafür eine entsprechende Testphase, die in diesem Jupyter Notebook zugunsten des Ziels zum Verstehen des Prinzips der Ermittlung personalisierter Filmempfehlungen reduziert wurde. Sofern bereits Vorkenntnissen zu ML bestehen, könnte an dieser Stelle etwa auch ein Bezug zu diesen Aspekten hergestellt werden. |
|
Jupyter Notebook (s.u.), |
| 3a | Überleitung zur exemplarischen Zweitverwertung:
Im Unterrichtsgespräch wird die Rolle der Daten in dem exemplarischen Kontext der Interaktion mit einem Streamingdienst, der ein Empfehlungsdienst nutzt, reflektiert – begrenzt auf die bisherigen betrachteten Facetten: Die Lernenden fassen die explizite und implizite Erhebung von Daten in diesem Kontext zusammen, beschreiben die Rolle des digitalen Doppelgängers sowie die Verarbeitung der erhobenen Daten sowie die Verwendung des digitalen Doppelgängers für den primären Zweck des Ermittelns von personalisierten Filmempfehlungen. Die Legitimität der Datenerhebung und -verarbeitung (und damit einhergehenden Notwendigkeit) kann an dieser Stelle sinnstiftend diskutiert werden; wenn man das Feature der personalisierten Startseite schätzt, ist eine Erhebung und Verarbeitung persönlicher Daten nötig. Dabei können etwa zwei Aspekte hervorgehoben werden: (1) Reduzieren der Informationsüberflutung (Finden einer personalisierten Auswahl von Produkten, die dem Nutzer/der Nutzerin auf der Plattform präsentiert wird.) sowie (2) Verbesserung des Nutzungserlebnisses (Positive Erfahrungen mit der Plattform führen dazu, dass die Nutzenden z.B. mehr Filme schauen und mit dem Streamingdienst somit mehr Umsatz generiert wird.) Bei der Bewertung kann dann auf die Zweitverwertung übergeleitet werden, da diese für die Bewertung ebenfalls relevant sein kann – kann zur Veranschaulichung der Betrachtung von sekundären Zwecken zusätzlich zu den primären Zwecken dienen. Didaktischer Kommentar: Mit dieser Zwischenreflexion soll zum einen das Verständnis für die Rolle der Daten in diesem Kontext hinsichtlich der Facetten von Datenbewusstsein gefestigt werden. Zum anderen wird durch diese Reflexion ermöglicht eine größere Perspektive einzunehmen, mit der die jeweiligen Aspekte verknüpft und die Bedeutung der Daten erkannt werden kann, was für eine spätere Evaluation nötig ist. |
|
|
| 3b | Einführung in das Rollenspiel als Diskussionsrunde bzgl. einer Zweitverwertung:
Nun stellt sich die Frage, wofür ein Anbieter eines Streamingdienstes die Daten bzw. den digitalen Doppelgänger zweitverwerten könnte (sekundärer Zweck). Diese Frage wird im Unterrichtsgespräch aufgeworfen.
Didaktischer Kommentar: In den vorherigen Teilen wurde die explizite und implizite Datenerhebung sowie deren Verarbeitung für den primären Zweck der Konstruktion einer Startseite thematisiert, wobei die Rolle des digitalen Doppelgängers aufgegriffen wurde. In diesem Teil wird nun exemplarisch ein sekundärer Zweck aufgegriffen und zusammen mit Aspekten der Wechselwirkung zwischen Nutzendem und Streamingdienst diskutiert. |
|
|
| 3c | Rollenspiel zur Zweitverwertung:
Ausgangssituation: Die Lehrkraft stellt das Rollenspiel mit der Ausgangssituation vor, welche auf dem AB3 notiert ist. Die Lernenden können direkt Fragen dazu stellen. Anschließend wird das AB3 an die Lernenden ausgeteilt. Die Lernenden bilden Gruppen, in denen sie sich mit den Rollen für das Rollenspiel befassen.
Die Lernenden bearbeiten in Gruppen die Rollen und bekommen dazu mit dem AB3 entsprechende Rollenkarten. [Folgende Rollen gibt es: Geschäftsführung, Leitung der technischen Abteilung, Leitung einer Forschungsabteilung, Leitung der Kundenbetreuung] Die Gruppen bearbeiten die zuvor beschriebene Ausgangssituation aus dem Blickwinkel der jeweiligen Rolle und u.a. eine Haltung zu diesem Vorschlag mit Argumenten festhalten (s. AB3). In der Spielphase vertreten die Lernenden ihre Rolle und diskutieren den Vorschlag der Ausgangssituation. Diese Diskussion wird von einem Moderator/einer Moderatorin geleitet, die insbesondere die Beteiligung aller Rollen an der Diskussion sicherstellen soll. Die Lernenden sind angehalten ihre Argumente unterzubringen und ihre besprochene Haltung zu vertreten. Alle anderen Lernende sind Beobachter und machen sich zu den Argumenten und den Perspektiven Notizen.
Auswertungsphase: Zu Beginn der Auswertung findet eine Abstimmung zur Frage statt, ob der Vorschlag umgesetzt werden sollte oder nicht. (Ergebnis sollte notiert werden) Anschließend bewerten die Lernenden die Rollen, kommentieren diese und reflektieren, welche Positionen und Argumente besonders wichtig waren. Es wird nun final abgestimmt, ob der Vorschlag umgesetzt werden sollte oder nicht. Die Lernenden formulieren abschließend ein persönliches Fazit zur Erhebung sowie Verarbeitung und Verwendung der Daten durch einen Streamingdienst. In der Diskussion sollten insbesondere die Aspekte bzgl. der Wechselwirkung zwischen Nutzendem und Streamingdienst bezogen auf den Einsatz eines Empfehlungsdienstes aufgegriffen werden.
In dem Rollenspiel wird ein sekundärer Zweck, der im Kontext der Streamingdienste vielleicht eher als fiktiv angesehen werden kann. Dennoch bietet die Diskussionsrunde zu dieser Situation den Anlass über verschiedene Aspekte bzgl. der Wechselwirkung zwischen Nutzendem und Streamingdienst zu diskutieren, wie etwa Effekte der Filterblasen oder bzgl. verstärkter Abhängigkeiten der Nutzenden. Die Lernenden sollen die Situation aus den verschiedenen Perspektiven betrachten und reflektieren. Dabei sollen die Lernenden eine begründete Haltung dazu entwickeln und die mögliche Verwendung und Verarbeitung der erhobenen Daten zum sekundären Zweck bewerten. |
|
AB3-Forschungs-abteilung, |
| 3d | Vertiefungs- oder Hausaufgabe (optional):
Geleitet durch Fragen reflektieren die Lernenden den Einsatz von Empfehlungsdiensten in ihrem Alltag und entwickeln dazu kontextabhängig eine Haltung. |
Vorbereitende Reflexion der Rolle der Daten sowie Bewertung des Einsatzes von Empfehlungsdiensten | AB-HA |
| 4a | Sammlung weiterer Beispiele mit Empfehlungsdiensten:
Im Plenum werden Beispiele für datengetriebenen digitale Artefakte aus dem Alltag der Lernenden gesammelt, in denen Empfehlungsdienste eingesetzt werden. Die können beispielsweise Feeds bei Social Media Plattformen, andere Plattformen aus dem Streamingbereich oder auch eine Suchmaschine sein. Didaktischer Kommentar: Den Lernenden soll es hiermit ermöglicht werden, dass sie ihre Vorstellungen über Empfehlungsdienste auf ihren Alltag insofern anwenden, dass sie diese Beispiele im Sinne datengetriebener digitale Artefakte identifizieren können, sodass erste Reflexionsprozesse angestoßen werden. Als Stütze kann dienen, dass Empfehlungsdienste im Sinne der individuellen Interaktion mit datengetriebenen digitalen Artefakten oft im Kontext der Personalisierung von Inhalten bzw. dessen Darstellung oder Auflistung wiederzufinden ist. |
|
Tafel, Beamer o.ä. |
| 4b | Anwendung der Facetten von Datenbewusstsein auf ausgewählte Beispiele aus ihrem Alltag:
Mithilfe des AB4 rekonstruieren die Lernenden nun für jeweils verschiedene Beispiele aus der vorherigen Sammlung (s. Phase 4a) die Rolle der Daten bei der Interaktion mit dem jeweiligen datengetriebenen digitalen Artefakt. Die Bearbeitung des AB4 findet wahlweise in Paaren oder Kleingruppen statt. Für die Bearbeitung sollten die Lernenden sich das jeweils gewählte datengetriebene digitale Artefakt anschauen können bzw. dazu recherchieren können. Die Wahl des zu untersuchenden Kontexts sollten die Lernenden selbst vornehmen können, es kann jedoch darauf geachtet werden, dass in der Lerngruppe insgesamt verschiedene Beispiele gewählt werden.
Die Lernenden sollen die Facetten von Datenbewusstsein (explizite und implizite Datenerhebung; primäre und sekundäre Zwecke sowie digitaler Doppelgänger) auf Beispiele aus ihrem Alltag anwenden. Damit wird der Transfer des Gelernten auf den eigenen Alltag sowie das Verknüpfen dessen mit eigenen Alltagserfahrungen gefördert. Außerdem soll dadurch angeregt werden, dass die Lernenden ihre alltäglichen Interaktionen mit datengetriebenen digitalen Artefakten reflektieren und erfahren, wie das Gelernte in alltäglichen Interaktionen angewendet werden könnte. |
|
AB4,
digitales Endgerät |
| 4c | Auswertung und Reflexion der weiteren Kontexte:
Ausgewählte Beispiele werden von den Lernenden im Plenum vorgestellt. Dabei sollen sie den Empfehlungsdienst vorstellen sowie ihre Entdeckungen/Vermutungen hinsichtlich der expliziten und impliziten Datenerhebung, der primären und sekundären Zwecke für die Verwendung und Verarbeitung dieser Daten sowie die Rolle des digitalen Doppelgängers erklären. Zu den vorgestellten Ergebnissen sollten Rückfragen gestellt sowie Ergänzungen der anderen Lernenden vorgenommen werden können. Abschließend sollen die Lernenden auch eine Bewertung der Datenerhebung und -verarbeitung in den jeweiligen Kontexten vornehmen, die durchaus sowohl auf einer individuellen als auch auf einer gesellschaftlichen Betrachtungsebene verortet werden können. Dafür soll im Unterrichtsgespräch diskutiert werden, inwiefern ein Nutzender in den jeweiligen Kontexten Handlungsmöglichkeiten hat sowie sich für Handlungen entscheiden kann (z.B. bestimmte Datenerhebungen oder Zwecke einschränken). Bei dieser Sicherung sollte hervorgehoben werden, dass in den verschiedenen Kontexten hinsichtlich der verschiedenen Arten der Datenerhebung sowie der verschiedenen Zwecke unterschiedliche Bewertungen und Haltungen dazu möglich sind, ein Nutzender sich für verschiedene Handlungen entscheiden kann und ggf. Einfluss auf die Datenerhebung und -verarbeitung vornehmen kann. Wichtig dabei sollte sein, dass die Lernenden ihre eigene Haltung dazu entwickeln und sie verstehen, dass es durchaus auch wichtig ist, eine eigene Entscheidung zu treffen (gerade keine Resignation fördern!). Im Rahmen dieser Phase könnte ggf. auch eine Zusammenfassung des gesamten Unterrichtsmoduls vorgenommen werden.
Es sollte auf eine korrekte Anwendung der Facetten von Datenbewusstseins geachtet werden, um Fehlvorstellungen zu vermeiden. Durch diese Phase sollen die Lernenden verschiedene Kontexte aus der Perspektive des Konzepts Datenbewusstsein (d.h. mit den Facetten die Rolle der Daten beschreiben und damit evaluieren können) betrachten und dadurch das Gelernte mit Erfahrungen aus ihrem Alltag verknüpfen können. Die Bewertung dieser Kontexte zielt dann darauf ab, dass die Lernenden erkennen, dass es einerseits verschiedene Handlungsoptionen bzw. Handlungsentscheidungen gibt und andererseits es wichtig ist eine eigene Entscheidung diesbezüglich zu treffen. Dabei sollte dringend beachtet werden, dass Lernenden weder ein Verhalten noch eine Meinung vorgeschrieben wird. Gleichermaßen sollte vermieden werden, dass Lernende eine Art Resignation gegenüber der Datenerhebung und -verarbeitung durch datengetriebene digitale Artefakte in ihrem Alltag entwickeln und sie durchaus handlungsfähig sind. |
|
Beamer o.ä. |
{kind=link}
Beschreibungen ausgewählter Materialien
Empfehlungsdienste im Allgemeinen (in engl.: Recommender System)
Ein Empfehlungsdienst verfolgt das Ziel die Menge aller vorhandenen Items (z.B. Filme, Musiktitel, Shopping-Produkte, …) auf eine Vorauswahl (Empfehlungen) einzuschränken, um den Nutzer:innen bei der Entscheidungsfindung zu unterstützen. Dem Nutzer/der Nutzerin sollten also nicht alle Items angezeigt werden, sondern nur eine Auswahl an Items, für die sich der Nutzer potenziell interessieren könnte, um eine Informationsüberflutung zu umgehen. Die Anbietenden des Dienstes zielt damit auf eine Gewinnmaximierung ab, indem der Nutzer/die Nutzerin „neue und interessante“ Items „entdeckt“. Dadurch werden die Nutzer:innen zu längeren und häufigeren Zugriffen (Steigerung der Nutzungszeit) angeregt, wodurch sie mehr Daten hinterlassen und womöglich der Umsatz durch Käufe oder Werbungen gesteigert werden kann.
Im Wesentlichen gibt es inhaltsbasierte (content-based), kollaborative (collaborative) und hybride Methoden zum Filtern der Items. Beim kollaborativen Filtern werden ähnliche Nutzer:innen identifiziert, um dann Empfehlungen basierend auf deren Daten (bspw. Filmbewertungen) zu ermitteln (hier etwa: Mittelwerte der Bewertungen der ähnlichen Nutzer:innen). Beim inhaltsbasierten Filtern werden Daten herangezogen, welche inhaltliche Informationen über die Produkte enthalten bzw. zumindest operationalisieren (z.B. Tags, Genres, Wortvorkommen in Textbeschreibungen). Das hybride Filtern verbindet verschiedene Methoden des kollaborativen und inhaltsbasierten Filterns – i.d.R. nacheinander.
Empfehlungsdienst in diesem Unterrichtsmodul
Explizite und implizite Bewertungen
Bewertungen für Produkte, wie bspw. Filme, können explizit oder implizit vorliegen. Explizit sind Bewertungen dann, wenn der Nutzer/die Nutzerin das Produkt direkt beurteilt, bspw. über ein Gefällt-mir-Button oder eine Sternebewertung. Dadurch gibt der Nutzer/die Nutzerin i.d.R. seine Meinung von dem Produkt bzw. sein Interesse an dem Produkt aktiv zum Ausdruck. Implizite Bewertungen werden nicht von dem Nutzer/der Nutzerin direkt angegeben. Das bedeutet, dass bestimmte Daten erhoben, generiert und verarbeitet werden, welche bspw. als Operationalisierung für das Interesse an dem Produkt dienen können. Beispiele für implizite Bewertungen sind: Hat der Nutzer/die Nutzerin das Produkt gekauft? Hat er oder sie den Film vollständig geschaut oder früher beendet? Wurde der Film mehrmals geschaut? Wurde sich das Produkt gemerkt (Merklisten)?
In dem Datensatz, welcher im Unterricht eingesetzt wird, wurden neben den expliziten Bewertungen zusätzlich implizite Beurteilungen generiert, um die beiden Konzepte zu veranschaulichen. Dabei sind implizite Filmbewertungen im Filmdatensatz die binäre Antwort auf die Frage, ob Nutzer:innen einen Film zu Ende geschaut hat oder nicht. Dieses neue Attribut wurde künstlich, jedoch auf Basis der vorhandenen Bewertungen angelegt. Mit einer Wahrscheinlichkeit von 85% wurden Bewertungen mit mehr als vier Sternen auf den Status “1” (Film zu Ende angeschaut) gesetzt. Liegt die Bewertung unter vier Sterne fand dies nur in 40% der Fälle statt. Alle übrigen Bewertungen erhielten den Status “0” (Film nicht zu Ende angeschaut). Im Anschluss wurden 25% der expliziten Bewertungen entfernt, um die Relevanz der impliziten Bewertungen darzustellen.
Genutzte Ratingdaten und Aufbereitung dieser für das Unterrichtsmodul
In diesem Unterrichtsmodul ziehen wir reale Nutzungsdaten von Nutzer:innen der Plattform MovieLens (movielens.org) heran. Auf der Plattform angemeldete Nutzer:innen können dort u.a. Filme bewerten und Filmempfehlungen bekommen. Es ist also ein Empfehlungsdienst eingebettet. Die Betreiber haben Bewertungsdaten öffentlich zugänglich gemacht . Für das Unterrichtsmodul haben wir diese Daten aus Performancegründen verkleinert, sodass wir lediglich ca. 50000 Bewertungen von ca. 5000 Usern zu insgesamt ca. 600 Filmen nutzen.
{kind=link}
Die Filme, die bewertet werden können, wurden manuell nach einer subjektiven Einschätzung des Bekanntheitsgrades sowie unter Einbezug von IMDB-Hitlisten ausgewählt. Filme, welche unter den möglichen Empfehlungen erscheinen, haben eines Mindestanzahl an Bewertungen erhalten. Die Nutzer:innen in dem Datensatz wurden so ausgewählt, dass sie alle mindestens einen der Filme, welche über das Empfehlungsmodul bewertet werden können, selbst bewertet haben. Grundsätzlich lag das Hauptaugenmerk bei der Datengenerierung auf der Balance zwischen der Performance des Modells und den für die Berechnungen verfügbaren Hardware-Ressourcen.
{kind=link}
Für das Unterrichtsmodul nutzen wir die Daten in Form von Datentabellen (DataFrames). Diese sind in den nebenstehenden Bildern dargestellt. Sie umfassen in der ersten Datentabelle Informationen über die Filme (Titel, Genre, Erscheinungsjahr) und in der zweiten Datentabelle gerade die explizit und implizit erhobenen Bewertungen der Nutzer:innen (Ids, Datum, Uhrzeit, Fertig_Angeschaut, Rating). Sowohl die Nutzer:innen als auch die Filme bekommen eine ID zugewiesen, mit der sie eindeutig identifiziert werden.
Jupyter Notebooks im Allgemeinen
Jupyter Notebooks ermöglichen das Ausführen von Pythoncode in Echtzeit mit Hilfe sogenannter Codezellen. Die Ergebnisse werden jeweils unter der aktuellen Zelle angezeigt. Erläuterungen zu Aufgaben zwischen den einzelnen Codezellen können auf Basis der Auszeichungssprache Markdown realisiert werden. Der gesamte Code kann dabei jederzeit manipuliert werden, was das spielerische Herantasten an Programmierung ermöglicht. Zu beachten ist, dass die Ausführung im Falle des Empfehlungsdienstes in diesem Modul nicht auf der lokalen Maschine, sondern auf dem zentralen Server der Universität Paderborn stattfindet.
Vorbereitetes Jupyter Notebook
Für dieses Unterrichtsmodul haben wir Bibliotheken entwickelt und ein Jupyter Notebook für den Unterricht vorbereitet. In diesem Jupyter Notebook (Empfehlungsdienst für Filme.ipynb) werden zunächst die Daten automatisiert eingelesen und ein Empfehlungsdienst am Beispiel von Netflix beschrieben. Anschließend ermitteln die Lernenden nach Eingabe von eigenen Bewertungen eigene Filmempfehlungen über einen bereits implementierten Empfehlungsdienst. Dieser basiert auf dem k-Nearest-Neighbor Algorithmus (Erklärung siehe unten) und nutzt als Basis seiner Vorschläge die vorgefilterten Bewertungsdaten. In der Standardeinstellung arbeitet der Dienst ausschließlich mit expliziten Bewertungen. Über einen Schalter im Code kann dieser jedoch die Empfehlungen auch basierend auf impliziten Bewertungen berechnen. Im nächsten Schritt wird die Frage behandelt, welche Daten erhoben wurden. Dafür können die Lernenden eine User-Movie-Tabelle (Erklärung siehe unten) aufrufen. Danach beschäftigt sich das Notebook mit der Frage, wie personalisierte Empfehlungen automatisiert berechnet werden können. Zur Visualisierung wird ein 2-dimensionales Koordinatensystem herangezogen. Darin können zwei Filme ausgewählt werden. Zu diesen Filmen werden dann alle vergebenen Bewertungen visualisiert. Somit sind einfache Analysen in Relation zur eigenen Bewertung möglich.
Alle nötigen Befehle werden in gelben Hinweisboxen erklärt. In blauen Boxen werden die Aufgaben detailliert formuliert und es werden grüne Einführungs- bzw. Erklärboxen eingeschoben.
Beim ersten Zugriff auf das Verzeichnis mit den Jupyter Notebooks muss man einen Login erstellen, mit dem zu einem späteren Zeitpunkt wieder an die letzte Bearbeitung angeschlossen werden kann. Andernfalls würden die Bearbeitungen nach schließen des Jupyter Notebooks gelöscht werden.
Das Verzeichnis ist unter folgendem Link zu erreichen: http://go.upb.de/Empfehlungsdienste (Hinweis: Der erste Login ist als Registrierung zu verstehen.)
k-Nearest-Neighbor Algorithmus zur Erstellung eines Modells
Der k-nearest-neighbor Algorithmus wird in dem vorbereitetem Jupyter Notebook mithilfe der Bibliothek sklearn zur Erstellung eines Modells verwendet. Dieses Modell kann anschließend zum Entscheiden von ähnlichen Nutzer:innen (eigentlich: nächsten Nachbarn) auf Basis von Daten aus z.B. einem Streamingdienst angewendet werden. Die konkrete Funktionsweise des Algorithmus wird im Unterricht nicht im Detail vermittelt, es soll lediglich die Idee der Vorgehensweise verstanden werden. An der Stelle der Modellerzeugung wird bewusst eine Black-Box gesetzt, um die im Rahmen dieser Unterrichtsreihe gesetzten Lernziele zu erreichen und keine Überforderung zu erzeugen.
{kind=link}
Beispiel:
In der nebenstehenden Tabelle ist ein Minimalbeispiel gegeben. Es gibt Bewertungsdaten von fünf Nutzer:innen zu zwei Filmen. Anhand dieses Beispiels kann bereits das Suche nach den k nächsten Nachbarn erklärt werden. Gesucht sind zum Beispiel zwei Nutzer:innen, die ähnlich zum markierten User 5 sind. Das sind dann etwa die User 1 und 4, da diese die kleinste Abweichung in ihren Bewertungen der beiden Filme zu User 5 haben. Konkret heißt das, dass die Abstände zwischen der Tabellenzeile von User 5 und denen von User 1 und 4 am kleinsten sind, die Differenz also möglichst klein ist. (Randnotiz: Mathematisch nutzen wir in unserer Umsetzung die euklidische Metrik für die Bestimmung von Abständen.)
{kind=link}
Dies kann auch in dem nebenstehenden Koordinatensystem visualisiert werden. Die Bewertungen zu Film A entsprechenden den Werten auf der x-Achse und zu Film B denen auf der y-Achse. So stellt jeder Punkt im Koordinatensystem einen User da, der beide Filme bewertet hat. Mit dieser Vorgehensweise können zu einem gewählten User die k ähnlichsten Nutzer:innen einfach identifiziert werden. So können im Koordinatensystem etwa beliebig viele Nutzer:innen hinzugefügt werden.
{kind=link}
Um nun anhand dieser ähnlicher Nutzer:innen zu User 5 für einen dritten Film C herausfinden, ob dieser empfohlen werden sollte, wird eine Prediction ermittelt. Die Prediction wird etwa durch den Mittelwert der Bewertungen des Films C der ähnlichen Nutzer:innen ermittelt. In dem Beispiel der nebenstehenden Tabelle ist dies dann 4,5 (Mittelwert von 4 und 5). Das heißt, wenn User 5 den Film C schauen und bewerten würde, würde er wahrscheinlich eine Bewertung von 4,5 abgeben. Dem User 5 sollte der Film C also durchaus empfohlen werden. Dieses (hier stark reduzierte) Verfahren ist auf eine große Anzahl von Nutzer:innen und Filmen übertragbar.
User-Movie-Tabelle als hilfreiche Tabelle zur Ermittlung von Empfehlungen
Die user-movie-Tabelle ist eine Datentabelle, die in diesem Kontext Filmbewertungen (Zellen) von Nutzer:innen (Zeilenweise userIds) zu den jeweiligen Filmen (Spaltenweise Filmtitel) aufführt. Diese Tabelle ist für den Empfehlungsdienst recht zentral, anhand dieser wird beispielsweise das vom k-Nearest-Neighbor Algorithmus ermittelte Modell mit einer aus der Tabelle erstellten sparse-Matrix berechnet. Ähnliche User werden also mithilfe der Abstände zwischen den jeweiligen Zeilen in dieser Tabelle bestimmt.