
Kategorie:ProDaBi/Projektkurs
Kurzbeschreibung
Das ProDaBi-Projekt führt seit dem Schuljahr 2018/2019 in Kooperation mit den Schulen Gymnasium Theodorianum Paderborn und Reismann Gymnasium Paderborn einen Projektkurs "Data Science und Künstliche Intelligenz" mit Schüler*innen der Q2 (12. Jahrgangsstufe) durch. Das Ziel ist dabei einerseits das Vermitteln von in der heutigen Zeit immer bedeutsamer werdenden Kenntnissen in den Bereichen Statistik, Datensammlung, Datenanalyse, maschinelles Lernen, Decision Trees und Künstliche Neuronale Netze sowie der Einsatz dieses Wissens zur Entwicklung einer eigenen KI-gestützten Anwendung.
Software-Produkt: Die KI-gestützte Anwendung
Als ein realitätsnahes Software-Projekt erhalten die SuS den Auftrag, eine Anwendung zu entwickeln, die die Parkplatzauslastung auf neun relevanten Parkplätzen in der Paderborner Innenstadt vorhersagen soll. Dabei erhalten die SuS vom Fraunhofer IEM Paderborn sowie den Unternehmen ASP und RTB Zugriff auf die aufgezeichneten Parkplatzdaten der letzten Jahre sowie auf die aktuelle Auslastung. Zusätzlich können sie weitere Daten wie Wetterdaten in Ihr Modell einbauen, um die Vorhersage zu optimieren.
Das Produkt des Projektkurses im Schuljahr 2020/2021 lässt sich hier entdecken.
Aufbau
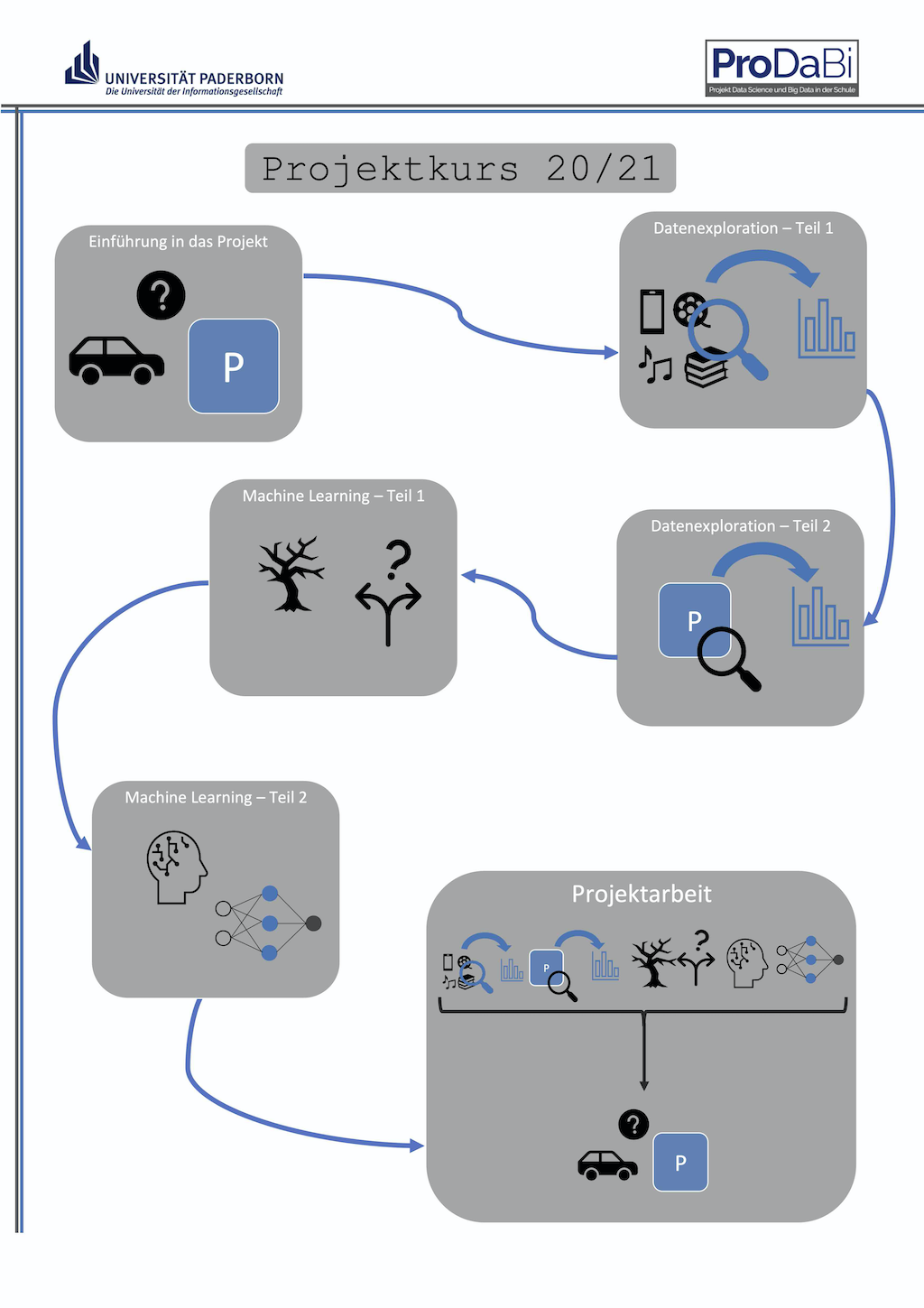
Der Projektkurs ist in 6 Module unterteilt, die verschiedene Aspekte von Data Science beleuchten. Die Module unterscheiden sich dabei insofern, als dass sich die Module 2-5 auf die Einführung wichtiger Konzepte und Methoden im Bereich Data Science und Künstliche Intelligenz beziehen, während in den Modulen 1 und 6 das hieraus entstandene Wissen zur Entwicklung der eigenen KI-gestützten Anwendung genutzt werden soll. Wichtig ist dabei auch zu wissen, dass die Projektarbeit - also das Erstellen der eigenen KI-gestützten Anwendung - nicht ausschließlich innerhalb des Moduls 6 geschieht, sondern während des gesamten Kurses parallel abläuft. In Modul 6 ist allerdings die gesamte Arbeit des Projektteams auf die Projektarbeit fokussiert.
Arbeiten mit SCRUM
Innerhalb des Projektkurses sind die SuS Teil eines SCRUM-Teams, welches sich in wöchentlichen Sprints organisiert. Ein Sprint besteht dabei aus den drei Aspekten "Sprint Review", "Sprint Retrospektive" und "Sprint-Planning". Während im "Sprint-Planning" die aktuell anliegenden Aufgaben geplant und auf das Team verteilt werden, werden die Aufgaben aus der Vorwoche im "Sprint-Review" hinsichtlich ihres Abschlusses überprüft und es werden verbleibende Rückfragen geklärt. Die "Sprint-Retrospektive" dient der Reflexion der Arbeit in der letzten Woche. Hier werden Absprachen bezüglich (zu verändernder) Arbeitsorganisation und Aufgabenverteilung besprochen. Weitere Informationen zum SCRUM-Vorgehensmodell befinden sich hier.
Arbeiten mit Worked Examples
Zur Erarbeitung einzelner Aspekte und Konzepte nutzen die SuS im Projektkurs sogenannte Worked Examples<ref>Atkinson, R. K., Derry, S. J., Renkl, A., & Wortham, D. (2000). Learning from Examples: Instructional Principles from the Worked Examples Research. Review of Educational Research, 70(2), 181–214.</ref>, die sie adaptieren und erweitern, um sich mit den jeweiligen Konzepten und Methoden vertraut zu machen. Die Worked Examples sind dabei vom ProDaBi-Team vorbereitet und umfassen ein lauffähiges Produkt, welches die SuS explorieren und nach ihren eigenen Interessen anpassen können.
Modulübersicht:
Modul 1: Einführung in das Projekt
In diesem ersten Modul werden die SuS in die Thematik des Projektkurses eingeführt.
Dazu gehören die folgenden Aspekte:
- Organisation des Projektkurses
- Sammeln von Vorstellungen und Vorerfahrungen im Bereich Data Science und Künstliche Intelligenz
- Vorstellen des Ablaufs (inhaltlich - anhand der Roadmap - s.o.)
- Vorstellen des Ablaufs (methodisch - anhand des CRISP-DM-Modells)
- Verständigung über das Vorgehen innerhalb von SCRUM
- Erste grobe Planung des Projektes:
- Vorstellung des "Ziel-Software-Produktes"
- Formulierung von User-Stories nach dem Schema "Ich als <Rolle> möchte mit der KI-gestützten Anwendung <Funktion>, um damit <Nutzen>."
- Aufbauend auf den User-Stories: Festhalten von Funktionen/Aspekten des angestrebten Produktes - unterteilt in "Must-Haves" und "Nice-to-Haves"
Modul 2: Datenexploration - Teil 1
Im ersten Modul zum Thema "Datenexploration" explorieren die SuS einen Datensatz, der mit einem adaptierten Erhebungsinstrument der JIM-Studie - eine Studie zum Medienumgang von Jugendlichen - an Paderborner Schulen erhoben wurde. Dabei entwickeln die SuS zunächst eigene Fragestellungen, zu denen sie auf Basis einer Auswertung der Daten im Tool CODAP Antworten finden sollen. Die SuS sammeln ihre Ergebnisse und Erkenntnisse und stellen sie dem Kurs in einer Präsentation vor.
Als "Gelenkstelle" zu Modul 3 fungiert die Aufgabe, Grenzen von CODAP zu reflektieren, indem die SuS Fragestellungen entwickeln sollen, zu deren Beantwortung die Funktionen von CODAP nicht ausreichen.
Modul 3: Datenexploration - Teil 2
In diesem zweiten Teil lernen die SuS Jupyter Notebooks als ein mächtiges, programmierbares Tool zur Datenanalyse kennen. Dabei nutzen sie Paderborner Parkplatzdaten aus den letzten Jahren, um erste Variablen herauszuarbeiten, die die Parkplatzauslastung in Paderborn beeinflussen. Die SuS erstellen dabei ein sogenanntes Computational Essay<ref>diSessa, A. A. (2000). Changing minds: Computers, learning, and literacy. Cambridge, Mass: MIT Press.</ref><ref>Odden, T. O., & Malthe-Sørenssen, A. (2021). Using computational essays to scaffold professional physics practice. European Journal of Physics, 42(1).</ref><ref>Wolfram, S. (2017, November 14). What Is a Computational Essay? [Blog Post]. Retrieved May 31, 2021 from https://writings.stephenwolfram.com/2017/11/what-is-a-computational-essay/</ref>, in dem sie ihre Datenanalyse dokumentieren, sodass man diese später auf interaktive Weise nachvollziehen kann. Die SuS programmieren die Datenanalyse in Python, wobei sie einem epistemischen Programmieransatz folgen, der einen Erkenntnisgewinn als Ziel des Programmierens in den Vordergrund stellt. Um sich mit der Programmier-Umgebung vertraut zu machen, durchlaufen die SuS zuvor einen Python-Online-Kurs sowie zwei Tutorial-Jupyter-Notebooks.
Die zwei essentiellen Python-Bibliotheken, die die SuS verwenden, sind einerseits Pandas zu Verwaltung der Datensätze und Plotly zur Visualisierung. Natürlich können die SuS auch weitere Bibliotheken einbinden, die ihnen bei ihrer Datenanalyse behilflich sind.
Modul 4: Machine Learning - Teil 1
Im ersten Machine-Learning-Teil lernen die SuS Decision Trees als eine Art des Machine Learnings kennen, mithilfe derer sich (einfache) Vorhersagen über einen bestimmten Sachverhalt getätigt werden können. Dabei entwickeln sie zunächst innerhalb von CODAP einen eigenen Decision Tree im Kontext des JIM-Datensatzes, welcher auch in Modul 2 verwendet wurde, bevor sie einen eigenen Algorithmus in den Jupyter Notebooks zur Vorhersage der Parkplatzauslastung für einen festen Parkplatz entwickeln - basierend auf der aktuellen Auslastung und der Variablen, die sie in der Datenexploration in Modul 3 als entscheident identifiziert haben.
Modul 5: Machine Learning - Teil 2
Im zweiten Teil lernen die SuS Künstliche Neurone Netze (KNNs) anhand einer enaktiven Aktivität "Brain in a Bag" als weitere Möglichkeit des Maschinellen Lernens kennen. Im Anschluss werden zudem das Feed-Forward-Prinzip und das allgemeine Lernprinzip von KNNs genauer beleuchtet. Dazu wird unter anderem die Exploration der dynamischen Oberfläche von Playground Tensorflow sowie zur Vertiefung das Erstellen einer Schrifterkennung für handgeschriebene Ziffern durchgeführt. Zur Umsetzung in Python verwenden die SuS die Keras-Bibliothek, wozu sie ebenfalls eine kurze Einführung erhalten.
Nachdem die SuS ein erstes KNN im Kontext der Parkplatzdaten in einem Jupyter Notebook erstellt haben, werden Vor- und Nachteile der beiden Machine Learning-Verfahren "Decision Trees" und "KNNs" abgewogen, um eine fundierte Entscheidung hinsichtlich des Einsatzes in der antizipierten KI-gestützten Anwendung zur Vorhersage der Parkplatzauslastung treffen zu können.
Modul 6: Projektarbeit
In diesem letzten Modul wenden die SuS ihre zuvor erworbenen Erkenntnisse an, um systematisch eine eigene Anwendung zur Vorhersage der Parkplatzauslastung in Paderborn zu erstellen. Dabei arbeiten sie nach und nach die "Must-Haves" und "Nice-to-Haves" aus dem Modul 1 in ihr Produkt ein. Gleichzeitig dokumentieren die SuS den Programmierprozess, indem sie ein Computational Essay im Hinblick auf die Entwicklung des Machine-Learning Algorithmus' erstellen. Dazu nutzen sie erneut Jupyter Notebooks, um den Prozess in den Code-Zellen festhalten und gleichzeitig gewonnene Erkenntnisse oder Erläuterungen zum Algorithmus in Markdown-Zellen beschreiben zu können.
Zum Ende erstellen die SuS eine Produktpräsentation, die sie dann der Allgemeinheit vorstellen. Essentieller Bestandteil ist dabei eine Demo der entwickelten KI-gestützten Anwendung, ein Blick in die Funktionsweise und Einsatzmöglichkeiten sowie eine Reflexion des Einsatzes von Künstlicher Intelligenz, Data Science und Maschinellem Lernen in Softwareprojekten.
Am Ende stellen die SuS neben der entwickelten Anwendung also auch eine Präsentation und ein digitales (Computational) Essay zur Verfügung, wodurch die Funktionen und Arbeitsweisen verdeutlicht werden und der Programmierprozess im Projektverlauf transparent wird. <references />
Diese Kategorie enthält zurzeit keine Seiten oder Medien.